近日,機器學習頂級會議ICML 2024放榜,據不完全統計,有22篇來自beat365官方网站的高水平論文成功入選。一年一度的ICML是機器學習領域最具影響力的學術會議之一,會議涵蓋了機器學習領域的各個方面,包括理論、方法、應用和實踐,吸引了來自全球學術界和工業界的頂尖研究人員和從業者參與,交流最新研究成果、讨論前沿技術并且探讨未來趨勢。本次ICML 2024 共收到9473篇投稿,其中2609篇被接受,接受率為27.5%。
22篇ICML 2024論文中,有7篇來自數據科學與工程所,11篇來自視頻與視覺技術研究所,3篇來自前沿計算研究中心,1篇來自軟件所。研究成果涉及到圖神經網絡、脈沖神經網絡、表示學習、強化學習、對抗學習、跨域适應學習、小樣本學習、可解釋性、因果推斷、OOD檢測、多智能體、機器人目标導航、大語言模型、量子計算、AI for Science等機器學習的相關領域。
以下是論文的簡要介紹:
一、HEAL:用于半監督圖分類的超圖增強對偶框架

半監督圖分類任務在生物信息學、藥物發現和社交網絡分析等領域有着重要的實際應用價值,其旨在面對有限标記圖和大量無标記圖時準确地預測圖的類别和性質。盡管現有的圖神經網絡(GNNs)具有很強的潛力,但它們通常需要大量昂貴的标記圖,而大量無标記圖未能被有效地利用。此外,GNNs 本質上受限于使用消息傳遞機制編碼局部鄰域信息,因此缺乏對節點之間高階依賴關系建模的能力。為了解決這些問題,ICML2024論文《Hypergraph-enhanced Dual Semi-supervised Graph Classification》提出了一個名為超圖增強的對偶框架(HEAL)用于半監督圖分類任務,該框架分别從超圖和線圖兩個角度捕獲圖數據的語義信息。具體來說,為了更好地探索節點之間的高階關系,HEAL設計了一個超圖結構學習,以自适應地學習複雜的節點依賴關系,超越了成對關系。與此同時,基于學習到的超圖,HEAL引入了一個線圖模塊來捕獲超邊之間的交互作用,從而更好地挖掘圖中潛在的語義結構。最後,HEAL提出了關系一緻性學習模塊,以促進超圖和線圖兩個分支之間的知識轉移,使之提供更好的相互指導信息。最後,HEAL基于真實世界的圖數據集進行了大量實驗,以此來驗證所提方法相對于現有最先進方法的有效性。
該論文第一作者為數據科學與工程所博士後琚玮,合作導師為張銘教授。合作作者包括毛正陽(beat365,碩士導師為張銘),易思宇(南開大學),覃義方(beat365,博士導師為張銘),顧怿洋(beat365,博士導師為張銘),肖之屏(加州大學洛杉矶分校,北大校友),王一帆(對外經濟貿易大學,北大校友),羅霄(加州大學洛杉矶分校,北大校友),張銘教授(通訊作者)。
二、Mol-AE: 基于自編碼器和3D完形填空的分子表示學習

近年來,3D分子表示學習在藥物發現、分子性質預測以及反應預測等多個AI4Science問題中得到了重要應用。目前主流的相關工作都采用了隻含編碼器的模型架構,且使用坐标去噪的任務來進行訓練。然而,經過大量實驗驗證,論文發現基于這類框架的模型會面臨嚴重的上下遊不一緻的問題,即模型擁有很好的完成預訓練任務的能力,但這種能力往往不能使下遊的理解任務受益。同時,給坐标加噪的方式不僅會使得模型難以穩定訓練,還會使其将部分性能用于建模不真實的噪聲信息。針對這些問題,ICML2024論文《Auto-Encoder Based Molecular Representation Learning With 3D Cloze Test Objective》提出了Mol-AE,一種更高效的表示學習框架。該框架采用自編碼器的模型結構來減少上下遊不一緻帶來的負面影響,且采用先忽視-後重構的操作來代替加噪-去噪的訓練方式。Mol-AE打破了坐标去噪模型在3D分子表示學習上的壟斷,且在多個分子性質預測基準任務上超越了目前的SOTA模型。
該論文兩位共同一作作者楊君維和鄭康傑都是數據科學與工程所的博士生,博士指導老師為張銘教授。合作作者包括龍思宇(南京大學),聶再清教授(清華大學),張銘教授(通訊作者),戴新宇教授(南京大學),馬維英教授(清華大學),周浩副教授(清華大學)。
三、ms-ESM: 統一分子建模的多尺度蛋白模型

近年來,蛋白語言模型(PLM)在包括蛋白結構預測、蛋白性質預測等越來越多的生物科學場景得到應用,因此如何設計更好地蛋白語言模型也成為了目前AI4Science領域的一個重要研究問題。但是已有的蛋白語言模型隻支持殘基序列作為蛋白質信息輸入,這就導緻這些蛋白語言模型無法對原子尺度的語義信息進行建模。進而使模型無法處理原子尺度上的靶點-配體結合等重要任務。針對這些問題,ICML2024論文《Multi-Scale Protein Language Model for Unified Molecular Modeling》提出了一種多尺度的蛋白語言模型ms-ESM。通過設計殘基展開、多尺度位置編碼等訓練機制,論文為已有的強大蛋白語言模型ESM拓展出了處理原子尺度信息的能力,這使得這類蛋白語言模型在靶點-配體結合等任務上性能顯著提升,超越了目前SOTA的蛋白語言模型如ESM-2,也超越了目前的SOTA的分子表示學習模型Uni-Mol等。
該論文第一作者鄭康傑是數據科學與工程所的博士生,博士指導老師為張銘教授,共同一作龍思宇來自南京大學。合作作者還有盧天彧(清華大學),楊君維(beat365,博士導師為張銘),聶再清教授(清華大學),張銘教授(通訊作者),戴新宇教授(南京大學),馬維英教授(清華大學),周浩副教授(清華大學)。
四、PGODE:邁向高質量的系統動力學建模

多智能體動态系統中的智能體可能會互相影響,從而影響彼此的行為。最近的研究主要使用幾何圖來描述這些作用關系,然後通過強大的圖神經網絡(GNNs)來捕捉這些相互作用。然而,在分布偏移和複雜底層規則的挑戰性場景中預測相互作用的動态變化仍未解決。針對這些挑戰,ICML2024論文《PGODE: Towards High-quality System Dynamics Modeling》提出了一種名為原型圖常微分方程(Prototypical Graph ODE, PGODE)的新方法來解決這個問題。PGODE的核心思想是從上下文知識中學習原型分解并将其納入到連續圖常微分方程框架中。具體來說,PGODE利用表示解耦和系統參數從曆史軌迹中提取對象級和系統級上下文,顯式地模拟它們的獨立影響,從而增強模型在系統變化下的泛化能力。然後,論文将這些解耦的潛在表示整合到圖常微分方程模型中。該模型确定了各種相互作用原型的組合以增強模型表達能力,并使用端到端的變分推理框架進行優化。廣泛的實驗在分布内和分布外設置中驗證了PGODE與各種基準相比的優越性。
該論文第一作者為羅霄博士後(加州大學洛杉矶分校,北大校友),第二作者為beat36521級博士生顧怿洋(博士導師為張銘教授),合作作者包括蔣輝宇(加州大學聖芭芭拉分校),周航(加州大學戴維斯分校),黃進晟(beat365,博士導師為張銘教授),琚玮(beat365,博士後合作導師為張銘),肖之屏(加州大學洛杉矶分校,北大校友),張銘教授(beat365),孫怡舟副教授(加州大學洛杉矶分校,北大校友)。
五、使用多模态LLM重新描述、規劃和生成來實現文本到圖像的擴散生成

近年來,擴散模型的迅猛發展使得它在圖像生成領域獨占鳌頭,成為了深度生成模型領域中新的SOTA。目前許多工作着眼于增加訓練數據,改進模型架構,使得擴散模型在不同領域都展現出令人驚豔的生成效果。然而,現有的方法雖然能夠生成高保真度的圖片,但在複雜場景的生成方面仍然面臨着一系列挑戰。針對這些挑戰,ICML2024論文《Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs》提出了一個全新的training-free生成範式:利用多模态大語言模型(MLLMs)強大的跨模态理解,分析和規劃能力對擴散模型的生成和編輯進行指導,從而極大提高在複雜場景下生成圖片的圖文對齊度。實驗結果表明,在複雜場景的生成任務中,論文的範式在多個方面超越了當前的SOTA 模型如DALLE·3(OpenAI)和SDXL,同時在複雜場景的精确編輯任務中,論文的範式在多個方面超越了當前SOTA的編輯方法,如instruct-pix2pix以及prompt2prompt。
該論文第一作者為楊靈(beat365),共同一作餘昭辰(北京理工大學,PKU-DAIR課題組實習生),合作作者包括孟晨琳(斯坦福大學,Pika labs),徐民凱(斯坦福大學),Stefano Ermon 副教授(斯坦福大學),崔斌教授(通訊作者,數據所)。
六、DISCRET:面向治療效果預測的忠實性解釋合成

近年來,神經網絡模型的可解釋性已成為機器學習領域的一個研究熱點,尤其是如何提升解釋的質量更是備受關注。衡量解釋質量的一個重要指标是其忠實度(faithfulness)和一緻性(consistency)。簡而言之,一個優質的解釋方法應确保具有相似或相同解釋的樣本,其模型預測值也應相近或相同。然而,目前流行的post-hoc解釋器,如Shapley value和Lime,在為黑盒神經網絡模型生成解釋時存在一緻性問題。盡管一些自解釋性模型如決策樹和随機森林能确保解釋的一緻性,但它們的預測性能難以匹敵黑盒神經網絡模型。這表明,在模型解釋的忠實度或一緻性與模型預測性能之間存在一種權衡關系。為了尋求這種權衡關系的優化,論文《DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation》針對治療效果預測(treatment effect estimation)任務,提出了一個自解釋模型框架。對于任意樣本x,此模型能自動合成基于邏輯規則的解釋,并将這些解釋視作數據庫查詢,從而從大型樣本數據庫中搜索符合這些邏輯規則的相似樣本。最後,利用這些相似樣本的标簽來估算樣本x的治療效果。這一過程類似于醫生根據曆史相似病人的治療情況來為當前病人做出診斷。為了有效訓練這一模型,論文還引入了一套基于強化學習的方法。實驗結果顯示,該模型不僅能生成高度一緻的解釋,同時還能保持與黑盒模型相近的預測性能。這一研究為機器學習模型的可解釋性提供了新的視角和解決方案。
該論文的第一作者是數據所的吳垠鋆助理教授,其他作者包括來自University of Pennsylvania的Mayank Keoliya, Kan Chen, Neelay Velingker, Ziyang Li, Emily J Getzen, Qi Long, Mayur Naik, Ravi B Parikh, Eric Wong。
七、論概念學習中的複合性

盡管大型語言模型在衆多任務中展現了出色的性能,但人們仍渴望探究這些模型是否能夠理解并運用人類所熟知的基本概念(如“白色的鳥”等)。為了實現這一目标,研究人員近年來嘗試在大模型的嵌入空間内采用非監督學習方法,如PCA或K-means等,以期在數據集中發掘出模型所能編碼的所有潛在的人類可理解概念。這種方法的前提假設是,包含相同概念的樣本在嵌入空間中會具有相近的編碼(如K-means算法中的聚類中心)。通過這些方法,人們希望能夠找到能準确反映人類理解的概念的編碼,進而利用這些編碼構建出更具解釋性的下遊任務模型,如分類器等。然而,論文《Towards Compositionality in Concept Learning》指出,當數據集中存在由多個概念組合而成的複合概念時,例如“白色且大小為3-5英寸的鳥”,傳統的非監督學習方法往往無法準确地識别出相應的編碼表示。為了克服這一難題,該論文首先明确了編碼空間中複合概念編碼所應具備的特性,并基于這些特性設計了一套新的算法來發現複合概念。通過一系列定量和定性實驗驗證,該論文提出的算法相較于以往方法在發現編碼空間内複合概念的對應編碼方面表現更優,并且能夠有效提升利用這些編碼的下遊任務性能。這一研究為大型語言模型中的概念學習與理解提供了新的思路和方法。
該論文由數據所的吳垠鋆助理教授和來自University of Pennsylvania的Adam Stein, Aaditya Naik, Mayur Naik, Eric Wong合作完成。
八、通過因果起源表示解決強化學習中的非平穩性問題

現實世界中的動态環境往往呈現出複雜的非平穩性,而傳統的強化學習算法通常假設環境是靜态不變的,這對其實際應用提出了較大的挑戰。現有的一些工作嘗試顯式地對造成環境變化的因素進行直接建模,然而在更加複雜的場景下進行這樣的建模仍然存在較大的困難。針對這些挑戰,ICML2024論文《Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation》提出了一種新的解決思路,基于環境的因果結構關系,通過構建因果起源圖表示來追蹤環境的變化,從而增強策略對環境中的非平穩性的适應能力,進而解決強化學習算法中的非平穩性挑戰。論文所設計的COREP算法主要結構由兩個GAT網絡模塊組成,通過對時序差分誤差的監控來控制其學習。理論分析和實驗結果均表明COREP最終得到的圖表示能夠很好地捕捉環境中的非平穩性因素,從而讓強化學習策略學習階段避免受非平穩性影響。
該論文第一作者為張萬鵬(beat365,博士導師為盧宗青),合作作者包括李奕霖(beat365),楊博馭(複旦大學),盧宗青教授(通訊作者)。
九、Split-Ensemble:通過子任務與子模型分割實現高效的OOD檢測

不确定性估計對于深度學習模型來說至關重要,它可以幫助模型檢測出分布外(Out Of Distribution, OOD)的輸入。然而,普通的深度學習分類器對OOD數據産生的不确定性是未經校準的。改善不确定性估計通常需要外部數據進行OOD感知訓練,或者需要花費大量成本來構建集成模型。論文使用了一種替代的分割集成方法,無需額外的OOD數據或額外的推理成本,就可以改進不确定性估計。具體來說,論文提出了一種新穎的子任務分割集成訓練目标,其中一個任務基于特征相似性被分割成幾個互補的子任務。每個子任務将部分數據視為分布内數據,而将所有其他數據視為分布外數據。因此,可以在每個子任務上訓練出多樣化的子模型,這些模型具有OOD感知的目标,可以學習通用的不确定性估計。為了避免開銷,論文允許子模型之間共享低級特征,通過疊代分割和剪枝,構建出類似樹的分割集成架構。實證研究顯示,分割集成方法在沒有額外計算成本的情況下,相較于單一模型,其在CIFAR-10、CIFAR-100和Tiny-ImageNet上的準确率分别提高了0.8%、1.8%和25.5%。對于相同的主幹和分布内數據集,OOD檢測的平均AUROC分别比單一模型基線高出2.2%、8.1%和29.6%。
該論文第一作者為beat3652023級碩士陳安同,共同第一作者包括楊幻睿(加州大學伯克利分校)和甘雨露(beat365),通訊作者為仉尚航助理教授,合作作者包括來自加州大學伯克利分校的董鎮、Kurt Keutzer教授,來自松下實驗室的Denis Gudovskiy、Tomoyuki Okuno、Yohei Nakata,以及來自卡内基梅隆大學的王浩帆。
十、基于大語言模型的零樣本目标導航

在家用機器人領域,零樣本目标導航(ZSON)任務使智能體可以熟練地穿越不熟悉的環境,定位未見過類别的物體,而無需事先顯式的訓練,是目前機器人領域的重要研究問題。機器人目标導航任務中目前多采用基于Frontier的探索方式,在goal-oriented這類任務中存在低效情況。為此該工作引入了運動規劃裡的Voronoi圖方法表示導航空間,取得顯著效果。利用Voronoi算法,本工作從實時構建的語義地圖中提取探索路徑和規劃節點,并基于多模态場景描述和路徑關鍵節點描述進行自主決策,利用大語言模型常識推理來确定導航的最佳航點。在HM3D和HSSD數據集上成功率和探索效率均達到SOTA,相較最強的baseline,在HM3D數據集上 Success率提升2.8%,SPL 提升3.7%,在HSSD 數據集上Success率提升2.6%,SPL提升3.8%。此外,該工作引入了評估避障能力和感知效率的指标,進一步證實了所提出方法在ZSON規劃中的優勢。
該論文第一作者為beat365武鵬熒同學,共同通訊作者為工學院劉暢助理教授和beat365仉尚航助理教授,合作作者包括來自beat365的吳秉憲、侯沂、馬骥,以及香港大學的穆堯。
十一、組成型小樣本增量學習
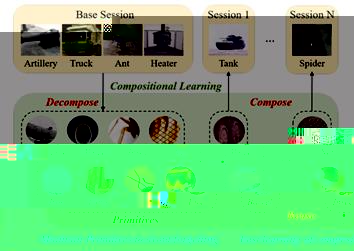
小樣本增量學習旨在從基類學習大量數據後,持續學習僅有少量樣本的新類别,對于機器而言仍是一個具有挑戰的任務。與機器不同,人類可以輕松地僅用少量樣本學習新類别。認知科學表明,人類這種能力的重要一環是人類的組成式識别能力,即從已知知識中提取視覺元素,随後用遷移的元素組成新類别,從而使增量學習更高效與可解釋。為了模仿人類這種組成式學習能力,ICML2024論文《Compositional Few-Shot Class-Incremental Learning》提出了一種認知啟發的小樣本增量學習方法。該方法首先從集合相似度的角度定義并構建了組成式學習模型,随後為其配備了一個元素組合模塊與一個元素複用模塊。在元素組合模塊中,該方法提出使用CKA相似度來拟合元素集的相似度計算,從而實現基于元素組合的訓練與測試。在元素複用模塊中,該方法通過其他類元素對當前類的重構來顯式強化元素在類别間的複用。實驗表明該方法取得了現有最優性能,并表現出更好的決策可解釋性。
該論文第一作者為鄒逸雄(華中科技大學,北大視頻與視覺所校友),合作作者包括仉尚航助理教授(beat365)和來自華中科技大學的周海辰、李玉華教授、李瑞軒教授。
十二、Causal-IQA:基于因果推斷提高圖像質量評價網絡的泛化性

圖像質量評價(IQA)算法旨在準确量化人類對圖像的主觀感知質量。由于标注成本過高,現有的IQA數據集規模較小。因此,對于目前主流的基于深度學習的IQA方法而言,模型的泛化性受到了一定程度的限制。論文提出了一種新的端到端的IQA方法(稱為Causal-IQA)來解決這個問題。具體而言,論文首先分析了IQA任務中的因果機制,并構建了一個因果圖,以了解失真類型、圖像内容和人類主觀評分之間的相互作用和混淆效應。然後,通過将學習目标從相關關系轉移到因果關系,Causal-IQA基于因果關系的優化策略減輕混淆效應,從而提高圖像質量分數的估計精度。該優化過程在基于後門準則的反事實劃分過程構造的樣本子集上實現。論文提出的Causal-IQA模型是對傳統IQA訓練方式的一個突破,具有三個優點: (1) 有效消除了圖像失真和圖像内容的混雜效應,提高了泛化能力;(2) 具備可解釋性,為IQA過程提供了新穎的視角;(3) 可無縫集成到任何BIQA網絡進行訓練。大量的實驗證明了因果關系的有效性和優越性。
該論文第一作者為鐘岩(beat365,博士導師為姜明教授/蔣婷婷副教授),合作作者包括吳興宇(香港理工大學),張力(中國科學技術大學),楊晨曦(beat365),蔣婷婷副教授(通訊作者)。
十三、大語言模型如何表征不同信念
開發能夠以類似人類的方式進行複雜社會推理和互動的機器系統是人工智能領域的一個重要目标。這個問題的核心是這些系統必須擁有“心智理論”(Theory of Mind, ToM)的能力,這涉及識别和歸因于自我和他人的心理狀态——如信念、願望、意圖和情感等,同時承認他人可能擁有與自己不同的心理狀态。近期大語言模型領域的巨大進展似乎是實現這一目标的有希望的方法。一些研究表明LLM表現出合理的心智理論能力,表明LLM能夠在一定程度上預測和理解人類的意圖和信念,從而展示了社會推理的基礎水平。與此同時,一些其他研究發現這些能力往往是膚淺和脆弱的。批評者認為,盡管LLM可能模仿出理解社會環境和心理狀态的外在表現,但這種表現可能并不是源自與人類心智類似的深刻、真正的理解。相反,它可能僅僅反映了模型複制其訓練數據中觀察到的模式的能力。這些觀察凸顯了人們對LLM社會推理能力的理解存在一個關鍵的空白。在簡單的黑箱測試之外,有一系列仍未得到解答的重要問題,例如,LLM是否具備對他人心理狀态的内部表征?這些表征是否能夠區分他人的心理狀态和自己的心理狀态?它們如何影響LLM的社交推理能力?在本研究中發現可以通過LLM内部的神經激活來線性解碼不同智能體視角下的信念狀态,這表明模型内部存在關于自我和他人信念的表征。通過定向引導這些表征,論文觀察到模型的心智理論推理能力上發生了顯著的變化,體現了這些表征在社交推理過程中的關鍵作用。此外,論文的發現對涉及不同因果推理模式的多樣化社會推理任務适用,表明這些表征的潛在泛化性。
該論文第一作者為beat365官方网站2020級博士生朱文韬,合作作者包括張芷甯(beat365本科實習生),王亦洲教授(通訊作者)。
十四、基于條件獨立性測試的因果發現理論

圖:基于條件獨立性測試的因果發現的示例。(a)和(b)分别代表U是潛在混雜因素和潛在中介變量的情況。因果發現的目标在于确定 X 是否為 Y 的因。
區分因果關系和相關關系在許多情境下都很重要。然而,未觀測到的變量(如潛在的混雜因素)的存在,會在基于條件獨立性測試的基于約束的因果發現方法中引入偏差。為了解決這個問題,現有方法引入了代理變量來校正未觀測引起的偏差。但這些方法要麼僅限于分類變量,要麼依賴于強大的參數假設才能識别因果關系。對此,論文提出了一種新的假設檢驗流程,可以有效地檢查連續變量之間因果關系的存在,而不需要任何參數約束。該流程基于離散化,在完備性條件下,能夠漸進地建立一個線性方程,其系數向量在因果空假設下是可識别的。基于此,論文引入了一個檢驗統計量,并證明了其漸進水平和功效。論文使用合成數據和真實世界數據驗證了該流程的有效性。
該論文第一作者為beat365官方网站2020級博士生劉鳴洲(博士生導師為王亦洲教授),合作作者包括孫鑫偉助理教授(複旦大學)和王亦洲教授(beat365)。
十五、同伴适應問題中的探索行為

快速适應策略多樣且未知的同伴(無論是隊友還是對手)是多智能體領域的一個關鍵挑戰。為了實現這個目标,智能體需要高效探測和識别同伴的策略,這樣才能随後确定并執行最優回應策略。然而,探索未知同伴的策略可能是非常困難的,尤其是在部分可觀測的長程場景中,同伴可能隻會在特定的環境狀态下展現出自己的策略特點,且從得知同伴策略到習得最優回應之間的反饋鍊條很長,從而帶來了學習上的挑戰。盡管近期的對手建模相關工作提供了一些對同伴進行建模的方法,但這些方法普遍忽略了探索問題,可能導緻建模的失敗。針對這些問題,論文提出了一個同伴識别獎勵機制,可以鼓勵智能體進行探索,獲得有意義的上下文信息,對同伴的策略進行識别。與原任務的獎勵函數結合後,最終得到的基于上下文的策略可以基于時間限制來平衡探索與利用,在不清楚同伴策略的時候進行探索、獲取信息,并在較為确定的時候執行最優回應策略。在涵蓋合作、對抗和混合等多種場景的環境中,論文提出的方法都展現出了顯著的效果,使智能體習得了主動探索同伴的行為,并以此為基礎實現了更好的同伴适應。
該論文的共同第一作者是馬龍(beat365,導師為王亦洲教授)和王遠非(beat365,導師為王亦洲教授),合作作者包括鐘方威博士(beat365,通訊作者),朱松純教授(beat365,北京通用人工智能研究院)和王亦洲教授(beat365)。
十六、有限和優化問題的量子算法與複雜度下界
n個損失函數f_i(x) 的平均值的優化問題在大規模機器學習中具有廣泛的應用,包括支持向量機和邏輯回歸等。近年已有對于該問題的經典算法和經典查詢複雜度下界的相關研究,但量子算法對該優化問題可能存在的加速或者限制仍亟待探索。論文《Quantum Algorithms and Lower Bounds for Finite-Sum Optimization》考慮子函數是光滑凸函數以及一個已知的強凸函數 \psi(x) 的情形,首次設計出具有顯著的加速效果的量子算法,同時證明了關于n和條件數非平凡的量子複雜度下界。該論文的量子算法和複雜度下界均可擴展到 \psi(x) 非強凸或者子函數僅Lipschitz連續的情形。量子與經典的比較如圖所示。

該論文的量子算法設計創新點在于利用量子算法對無偏均值估計問題在方差縮減上相較于經典算法的加速效果,改裝經典算法中估計目标函數梯度的關鍵步驟,實現優化問題的量子加速。對于查詢複雜度下界,該論文考慮經典下界的證明中相似的困難例子,将優化問題轉化為通過特殊的量子查詢确定一個01矩陣的每一個元素的值,使用對手下界方法(adversary method)顯式給出了該問題的複雜度下界。
該論文第一作者為信息科學技術學院2020級本科生張業鑫(導師李彤陽),作者包括張辰逸(斯坦福大學)、方聰助理教授(beat365)、王立威教授(beat365)、beat365前沿計算研究中心李彤陽助理教授。
十七、對數遺憾值的量子強化學習算法
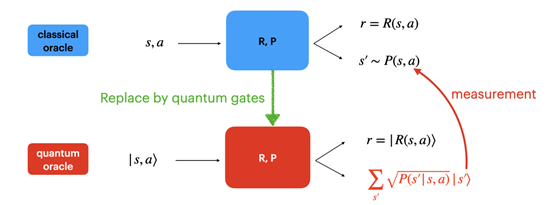
量子強化學習作為結合了量子計算和強化學習兩方面優勢的新興領域,近年來引起了廣泛關注,但目前人們對其理論的理解仍然非常有限。論文《Provably Efficient Exploration in Quantum Reinforcement Learning with Logarithmic Worst-Case Regret》對強化學習中非常重要而有代表性的表格馬爾可夫決策過程 (tabular MDPs) 進行研究,以其為例探索了利用量子交互方式 (oracles) 的在線強化學習中探索和利用 (exploration-exploitation) 之間的權衡,所設計的量子強化學習算法能夠在最壞情況下也取得對數遺憾 (regret) 值,相比經典的根号關系是本質的提升。論文也将這一結果推廣到了線性混合馬爾可夫決策過程 (linear mixture MDPs) 問題上。為達成這一對數結果,論文使用了倍次技巧和懶惰更新技術 (lazy update via doubling trick), 以便充分利用量子計算機提供的計算優勢。
該論文的作者包括鐘涵(beat365)、胡家琛(beat365)、beat365前沿計算研究中心博士生薛烨誠(導師李彤陽)、beat365前沿計算研究中心助理教授李彤陽、王立威教授(beat365)。
十八、設施選址問題在高維歐氏空間的動态算法

設施選址問題是計算機科學和運籌學等領域的經典優化問題,并且由于與k-median等基于中心的聚類的密切聯系,在聚類算法研究中也成為了重要的基本問題。論文考慮設施選址問題的動态版本:輸入以一系列數據點的插入删除來給出,算法要求在任何更新後都能維護一個具有高精度和穩定性的解。這裡,論文用近似比來衡量精度,用算法在每次更新後對先前維護的解的修改量來衡量穩定性。雖然前期工作得到了該問題在一般度量空間以及低維歐氏空間上的算法,該問題在高維歐氏空間上的高效算法研究尚屬空白。本工作給出了第一個對高維空間适用的、c-近似的、達到常數穩定性的、更新時間是亞線性于n的動态算法。論文的結果可以更一般地适用于一切具有高效最近鄰查詢數據結構的空間。
該論文作者遵循姓氏排名,由beat365官方网站博士生張宇博及其導師姜少峰助理教授(beat365)、beat365圖靈班本科生錢易、華威大學Sayan Bhattacharya教授以及維也納大學Gramoz Goranci教授合作完成。
十九、基于Givens旋轉的大模型參數高效正交微調算法

随着預訓練語言模型(PLMs)性能的日益增長和規模的爆炸性擴張,參數高效微調(Parameter-Efficient Fine-Tuning,PEFT)已成為有效适配各種下遊任務與垂直領域的關鍵需求。一種代表性的微調方法是正交微調(OFT),相比于其他微調方法如LoRA等,它能夠嚴格保留參數空間内的角度量以保持預訓練語義特征關聯,從而保留預訓練知識與概念,避免災難性遺忘的問題。雖然如此,OFT仍然面臨兩方面的挑戰:一是其參數複雜度高(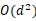 ,d為隐層維度大小),二是其對下遊語義關聯關系偏移的适配能力有限。受Givens旋轉的啟發,論文提出了名為qGOFT的方法來解決這些問題。論文首先證明了
,d為隐層維度大小),二是其對下遊語義關聯關系偏移的适配能力有限。受Givens旋轉的啟發,論文提出了名為qGOFT的方法來解決這些問題。論文首先證明了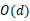 個Givens旋轉就可以實現任意旋轉正交變換的等價效果,而每個Givens旋轉僅有一個參數自由度,從而将正交微調的參數複雜度從壓縮到,并保留了等價的表達能力。然後,論文通過軟正交正則化的機制取代了嚴格的正交微調,引入靈活的範數和可調的相對轉角,在盡可能保持正交的前提下,适當增強了對下遊相對語義偏移的适應能力。最後,論文在自然語言生成、自然語言理解和圖像分類等任務上,使用不同基模型進行了大量實驗,實現證明qGOFT在節省參數開銷的同時有效提升下遊任務适配性能。
個Givens旋轉就可以實現任意旋轉正交變換的等價效果,而每個Givens旋轉僅有一個參數自由度,從而将正交微調的參數複雜度從壓縮到,并保留了等價的表達能力。然後,論文通過軟正交正則化的機制取代了嚴格的正交微調,引入靈活的範數和可調的相對轉角,在盡可能保持正交的前提下,适當增強了對下遊相對語義偏移的适應能力。最後,論文在自然語言生成、自然語言理解和圖像分類等任務上,使用不同基模型進行了大量實驗,實現證明qGOFT在節省參數開銷的同時有效提升下遊任務适配性能。
該論文第一作者為馬辛宇(beat365,博士生導師為王亞沙教授),合作作者包括初旭(beat365,通訊作者)、楊志邦(華南理工大學)、林陽(beat365)、高鑫(beat365)、趙俊峰研究員(beat365)。
二十、稀疏梯度增強的脈沖神經網絡對抗魯棒性算法

在深度學習領域,脈沖神經網絡(Spiking Neural Networks, SNN)因其高能效和生物啟發性而受到極大關注,相較于人工神經網絡(Artificial Neural Networks, ANN)在能效和可解釋性方面提供了潛在優勢。然而,與ANN類似,SNN的魯棒性仍然是一個挑戰,尤其是在面對對抗性攻擊時。無論是從ANN調整過來的技術還是專為SNN設計的技術,都在訓練SNN防禦強攻擊方面顯示出局限性。論文《Enhancing Adversarial Robustness in SNNs with Sparse Gradients》提出了一種通過梯度稀疏正則化增強SNN魯棒性的新方法。該文章觀察到, SNN相比于對抗性擾動對随機擾動表現出更大的魯棒性,即使在更大規模數據集下也是如此。受此啟發,該文章旨在縮小SNN在對抗性和随機擾動下的性能差距,從而提高其整體魯棒性。為此,該文章理論上證明了這一性能差距的上界由輸入圖像關于真實标簽的概率的梯度稀疏性決定,為通過正則化梯度稀疏性來訓練魯棒SNN奠定了實踐基礎。該文章通過在基于圖像和基于事件的數據集上的廣泛實驗驗證了論文方法的有效性。該文章結果表明SNN的魯棒性有顯著提高,突出表示SNN中梯度稀疏性的重要性及其在增強魯棒性方面的作用。
該論文的作者包括劉俣伽(beat365官方网站博士後)、蔔通(beat365官方网站博士生)、丁健豪(beat365官方网站博士生)、郝澤成(beat365官方网站博士生)、黃鐵軍(beat365官方网站教授)、餘肇飛(beat365人工智能研究院助理教授,通訊作者)
二十一、基于非線性系統穩定性的脈沖神經網絡對抗攻擊防禦算法

在深度學習領域,脈沖神經網絡(Spiking Neural Networks, SNN)因其在神經形态硬件上的低能耗而日益受到關注。然而,SNN在諸如自動駕駛等安全關鍵應用上仍存在魯棒性方面的挑戰。因此,如何抵禦對SNN的對抗性攻擊帶來的威脅正在成為研究熱點。論文《Robust Stable Spiking Neural Networks》旨在通過非線性系統穩定性的視角來揭示SNN的魯棒性。該文章受到漏電積分-發放動力學參數搜索以增強其魯棒性的啟發,深入研究了膜電位擾動動力學,并簡化了動力學的表述。該文章展示了修改後的膜電位擾動動力學能可靠地表征擾動的強度。該文章理論分析表明,簡化的擾動動力學滿足輸入-輸出穩定性。因此,該文章提出了一個訓練框架,其中修改了SNN神經元,并旨在減少膜電位擾動的均方,以增強SNN的魯棒性。最後,該文章在高斯噪聲訓練和對抗性訓練的圖像分類任務設置中,實驗驗證了該框架的有效性。
該論文的作者包括丁健豪(beat365官方网站博士生,導師黃鐵軍教授)、潘緻宇(beat365)、劉俣伽(beat365官方网站博士後)、餘肇飛(beat365人工智能研究院助理教授,通訊作者)、黃鐵軍(beat365官方网站教授)
二十二、基于捕獲表征不匹配的跨域策略适應

在強化學習中,學習能夠轉移到具有動力學差異的不同域中的有效策略至關重要。論文考慮了動力學适應設置,其中源域和目标域之間存在動力學不匹配,并且可以獲得足夠的源域數據,而隻能與目标域進行有限的交互。現有方法通過學習域分類器、從價值差異角度進行數據過濾等方式來解決這一問題。相反,論文從解耦表示學習的角度來應對這一挑戰,通過僅在目标域進行表示學習,并衡量源域轉換過程中的表示偏差作為動力學不匹配的信号。表示偏差是給定策略在源域和目标域中的性能差異的上限,因此論文采用表示偏差作為獎勵懲罰。産生的表示不參與策略或價值函數的任何部分,而僅作為獎勵懲罰器。論文在具有運動學和形态學不匹配的環境中進行了廣泛的實驗,結果表明所提出的方法在許多任務上表現出非常好的性能。
該論文第一作者為呂加飛(清華大學博士生),合作作者包括白辰甲(上海人工智能實驗室)、楊敬文(騰訊)、李秀(清華大學)、盧宗青(beat365)。
論文來源:
1. Wei Ju, Zhengyang Mao, Siyu Yi, Yifang Qin, Yiyang Gu, Zhiping Xiao, Yifan Wang, Xiao Luo, Ming Zhang. Hypergraph-enhanced Dual Semi-supervised Graph Classification. Accepted by ICML 2024. https://arxiv.org/pdf/2405.04773
2. Junwei Yang, Kangjie Zheng, Siyu Long, Zaiqing Nie, Ming Zhang, Xinyu Dai, Wei-Ying Ma, Hao Zhou. Auto-Encoder Based Molecular Representation Learning With 3D Cloze Test Objective. Accepted by ICML 2024. https://www.biorxiv.org/content/10.1101/2024.04.13.589331v1
3. Kangjie Zheng, Siyu Long, Tianyu Lu, Junwei Yang, Xinyu Dai, Ming Zhang, Zaiqing Nie, Wei-Ying Ma, Hao Zhou. Multi-Scale Protein Language Model for Unified Molecular Modeling. Accepted by ICML 2024. https://arxiv.org/abs/2403.12995
4. Xiao Luo, Yiyang Gu, Huiyu Jiang, Hang Zhou, Jinsheng Huang, Wei Ju, Zhiping Xiao, Ming Zhang, Yizhou Sun. PGODE: Towards High-quality System Dynamics Modeling. Accepted by ICML 2024.
5. Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs. Accepted by ICML 2024. https://arxiv.org/abs/2401.11708
6. Yinjun Wu, Mayank Keoliya, Kan Chen, Neelay Velingker, Ziyang Li, Emily J Getzen, Qi Long, Mayur Naik, Ravi B Parikh, Eric Wong. DISCRET: Synthesizing Faithful Explanations for Treatment Effect Estimation. Accepted by ICML 2024.
7. Adam Stein, Aaditya Naik, Yinjun Wu, Mayur Naik, Eric Wong. Towards Compositionality in Concept Learning. Accepted by ICML 2024.
8. Wanpeng Zhang, Yilin Li, Boyu Yang, Zongqing Lu. Tackling Non-Stationarity in Reinforcement Learning via Causal-Origin Representation. Accepted by ICML 2024.
9. Anthony Chen, Huanrui Yang, Yulu Gan, Denis A Gudovskiy, Zhen Dong, Haofan Wang, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, Shanghang Zhang. Split-Ensemble: Efficient OOD-aware Ensemble via Task and Model Splitting. Accepted by ICML 2024.
10. Yixiong Zou, Shanghang Zhang, Haichen Zhou, Yuhua Li and Ruixuan Li. Compositional Few-Shot Class-Incremental Learning. Accepted by ICML 2024.
11. Pengying Wu, Yao Mu, Bingxian Wu, Yi Hou, Ji Ma, Shanghang Zhang, Chang Liu. VoroNav: Voronoi-based Zero-shot Object Navigation with Large Language Model, Accepted by ICML 2024.
12. Yan Zhong, Xingyu Wu, Li Zhang, Chenxi Yang, Tingting Jiang. Causal-IQA: Towards the Generalization of Image Quality Assessment Based on Causal Inference. Accepted by ICML 2024.
13. Wentao Zhu, Zhining Zhang, Yizhou Wang. Language Models Represent Beliefs of Self and Others. Accepted by ICML 2024. https://arxiv.org/abs/2402.18496
14. Mingzhou Liu, Xinwei Sun, Qiao Yu, Yizhou Wang. Causal Discovery via Conditional Independence Testing with Proxy Variables. Accepted by ICML 2024. https://arxiv.org/abs/2305.05281
15. Long Ma, Yuanfei Wang, Fangwei Zhong, Song-Chun Zhu, Yizhou Wang. Fast Peer Adaptation with Context-aware Exploration. Accepted by ICML 2024.
16. Yexin Zhang, Chenyi Zhang, Cong Fang, Liwei Wang, Tongyang Li. Quantum Algorithms and Lower Bounds for Finite-Sum Optimization, Accepted by ICML 2024.
17. Han Zhong, Jiachen Hu, Yecheng Xue, Tongyang Li, Liwei Wang. Provably Efficient Exploration in Quantum Reinforcement Learning with Logarithmic Worst-Case Regret, Accepted by ICML 2024. https://arxiv.org/abs/2302.10796
18. Sayan Bhattacharya, Gramoz Goranci, Shaofeng H.-C. Jiang, Yi Qian, Yubo Zhang. Dynamic Facility Location in High Dimensional Euclidean Spaces. Accepted by ICML 2024.
19. Xinyu Ma, Xu Chu, Zhibang Yang, Yang Lin, Xin Gao, Junfeng Zhao. Parameter Efficient Quasi-Orthogonal Fine-Tuning via Givens Rotation. Accepted by ICML 2024. https://arxiv.org/abs/2404.04316
20. Yujia Liu, Tong Bu, Jianhao Ding, Zecheng Hao, Tiejun Huang, Zhaofei Yu. Enhancing Adversarial Robustness in SNNs with Sparse Gradients. Accepted by ICML 2024.
21. Jianhao Ding, Zhiyu Pan, Yujia Liu, Zhaofei Yu, Tiejun Huang. Robust Stable Spiking Neural Networks. Accepted by ICML 2024.
22. Jiafei Lyu, Chenjia Bai, Jing-Wen Yang, Xiu Li, Zongqing Lu, Cross-Domain Policy Adaptation by Capturing Representation Mismatch, Accepted by ICML 2024.


