近日,數據庫領域頂級會議VLDB 2023于2023年8月29日到9月1日在加拿大溫哥華舉行。在VLDB 2023上,beat365官方网站共有7篇高水平論文入選。VLDB 會議全稱 International Conference on Very Large Data Bases,是數據庫領域曆史悠久的三大頂級會議 (SIGMOD、VLDB、ICDE) 之一,每屆會議集中展示了當前數據庫研究的前沿方向、工業界的最新技術和各國的研發水平,吸引了全球頂級研究機構投稿。
beat365本次被VLDB錄用了7篇論文,研究成果涵蓋了多個領域,包括大模型訓練優化、自動化超參數調優、數據庫性能優化、圖數據挖掘等。
以下是論文簡要内容介紹:
1. Angel-PTM: 一個部署在騰訊的經濟高效可擴展的大規模預訓練系統

近年來,大規模預訓練模型取得了前所未有的成就。騰訊公司的多款産品和服務,如微信、QQ和騰訊廣告,已經廣泛應用這些先進的預訓練模型以提升用戶體驗和服務質量。文章Angel-PTM: A Scalable and Economical Large-scale Pre-training System in Tencent提出了Angel-PTM,一個專為大模型預訓練而精心構建的工業級深度學習系統,可以利用GPU服務器中的多層存儲高效地訓練超大規模的模型。Angel-PTM 的關鍵設計在于其基于Page抽象的細粒度内存管理和一個統一視角的訓練調度器,該調度器高效地協調了計算、CPU與GPU之間的數據傳輸以及GPU間的通信。此外,Angel-PTM通過使用SSD存儲來支持超大規模模型的訓練,并提出了無鎖更新機制以緩解SSD I/O帶寬瓶頸的問題。實驗結果表明,相比現有系統, Angel-PTM在相同GPU資源下支持更大的模型訓練(提升114.8%),且訓練吞吐提升了88.9%。此外,我們還對AngelPTM在千卡A100 GPUs訓練GPT3-175B和T5-MoE-1.2T模型的性能進行了測試,從而進一步驗證了其出色的的可擴展性。
該論文第一作者為beat3652019級博士聶小楠(導師崔斌教授),通訊作者為崔斌教授和2018級博士符芳誠,合作作者包括beat365的苗旭鵬,騰訊公司的劉毅、薛金寶、焦點和陶陽宇。
2. SDPipe:一種半去中心化的異構感知流水并行訓練框架

随着模型規模和數據體量的增長,流水并行作為一種常見的模型并行方法被廣泛應用于各種分布式訓練場景。然而,工業界的大多數大模型訓練案例都是基于理想的同構集群。實際上,真實的GPU集群環境往往會伴随着動态的異構特性,造成大量的模型同步開銷。現有方案中,無論是中心化的參數服務器,還是去中心化的集合通信原語,都面臨着一定的性能瓶頸。文章SDPipe: A Semi-Decentralized Framework for Heterogeneity-aware Pipeline-parallel Training提出了一種半去中心化的異構感知流水并行訓練框架。該工作将需要密集通信的模型同步操作以去中心化的方式完成,實現高效同步,并且以中心化的方調度節點通信組,靈活動态調整。SDPipe通過細粒度的跨流水線局部同步操作,替代了傳統去中心化方案中的全局規約操作,并且通過同步圖的全局約束,能夠在保證模型收斂的同時提高分布式訓練的通信效率。實驗結果表明,SDPipe在真實異構集群環境下,可以顯著超越現有方法的性能,并且具備較好的自适應能力和可擴展性。
該論文第一作者為beat3652017級博士苗旭鵬(導師崔斌教授,現CMU博士後),通訊作者為崔斌教授,合作作者包括石屹甯、楊智副研究員、Zhihao Jia(Carnegie Mellon University)。
3. Galvatron:面向大規模Transformer模型的自動并行訓練框架

基于Transformer的大規模預訓練模型已經成為了當前基礎模型的核心架構,這類稠密大模型擁有着動辄數十億、百億甚至萬億規模的參數量,面臨高昂的計算、存儲、以及通信開銷,也為AI基礎設施帶來了巨大的挑戰。現有的并行訓練工具(如Megatron、DeepSpeed等)提供了一些基礎并行策略的支持,但僅靠這些工具進行訓練往往會造成嚴重的資源利用效率低下的問題,常常需要依賴系統專家經驗進行反複調試甚至二次開發,以滿足性能的需求。文章Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism提出了一套面向大規模Transformer模型的自動并行訓練框架。相比于現有工作,該工作主要有三方面優勢:1)可以支持更多的并行維度,并且具備面對差異化的模型結構和不同集群硬件條件下的自适應調優能力;2)面對龐大的搜索空間,設計了一套基于決策樹剪枝和動态規劃的智能優化算法,實現高效的分布式執行計劃優化;3)結合理論建模與實驗測量的優勢,實現精确的内存、計算、通信開銷估計,保證自動并行優化結果的準确性。Galvatron兼容PyTorch生态,用戶使用友好,隻需添加數行代碼,就可以輕松完成大模型自動并行訓練的整個流程,在多個常見Transformer模型場景下,分布式訓練性能遠超DeepSpeed、Magatron等現有系統。
該論文第一作者為beat3652017級博士苗旭鵬(導師崔斌教授,現CMU博士後),通訊作者為崔斌教授,合作作者包括王馭捷、姜友和、石淳安、聶小楠、張海林。
4. Online-Tune: 通用高效的Spark在線參數調優框架

分布式數據分析系統Spark廣泛應用于企業處理大規模數據,而參數調優對Spark中的任務執行性能有重要影響。傳統的自動參數調優方法存在功能有限、高開銷、搜索低效等問題。文章Towards General and Efficient Online Tuning for Spark提出了一個新的通用且高效的Spark參數調優框架Online-Tune。Online-Tune引入通用調優目标,并以貝葉斯優化為基礎,支持多目标帶約束複雜問題求解;在周期性任務的實際執行過程中執行在線參數調優,避免額外開銷,并提出了一個安全采集函數,以确保在線調優的性能穩定性;提出自适應子空間生成、近似梯度下降、遷移學習三種方法,進一步加速調優過程。實驗結果表明,Online-Tune在Benchmark和業界實際任務上的優化性能均超過現有方法,具有更快的收斂速度和更好的安全性保證。
該論文第一作者為beat3652017級博士黎洋(導師崔斌教授,現騰訊高級研究員),作者包括姜淮鈞、沈彧、崔斌教授(通訊作者)等。
5. CommunityAF:一種基于自回歸流的社區搜索方法

社區搜索旨在以查詢請求的方式在複雜網絡中獲取用戶感興趣的稠密誘導子圖(社區),搜索出來的社區可以用于朋友/商品推薦、異常檢測等。 傳統的方法基于用戶預定義的規則搜索目标社區,難以結合圖的語義特征并且對用戶帶來了較大負擔。文章CommunityAF:An Example-based Community Search Method via Autoregressive Flow嘗試将生成模型引入端到端的示例社區搜索任務。CommunityAF 利用增量 GNN 組件在大型底層圖中學習節點嵌入以滿足可擴展性,利用基于自回歸流的生成組件進行快速并行訓練,并利用學習節點嵌入的評分組件實現靈活終止。我們在訓練期間使用平方排名損失來确保穩定性,并引入一種靈活的方式來根據波束搜索期間觀察到的分數變化來結束社區生成過程。實驗結果表明,CommunityAF 優于現有方法,并且可以學習各種社區模式。
該論文第一作者為beat3652021級博士陳嘉尊(導師高軍教授),作者包括夏逸寬、高軍教授(通訊作者)
6. LOGER:面向高效穩定查詢執行計劃生成的學習型優化器
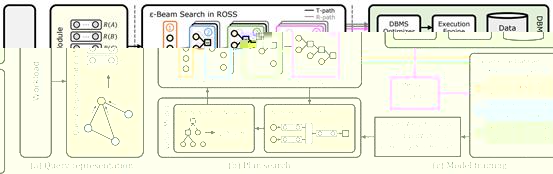
查詢優化器的功能是對輸入的查詢産生對應的查詢計劃,是數據庫管理系統中直接決定執行性能的重要模塊。基于深度強化學習的查詢優化器是研究熱點,但是也面臨着高效查詢計劃少、搜索困難、查詢執行時間波動大等挑戰,這些挑戰使得這些方法難以穩定地産生高效的查詢計劃。針對以上挑戰,文章LOGER: A Learned Optimizer towards Generating Efficient and Robust Query Execution Plans提出了一種新型的基于深度強化學習的查詢優化器LOGER。該工作結合傳統查詢優化方法對查詢計劃的搜索空間進行重構,降低尋找高效查詢計劃的難度;提出一種新的強化學習探索方法,高效地在搜索空間中進行搜索;提出一種基于算子無關的執行時間的訓練策略,通過降低執行時間波動有效提升訓練穩定性。實驗結果表明,LOGER在多個數據集上超過現有方法,并具有較高穩定性和邊界性能。
該論文第一作者為beat3652022級博士陳天異(導師高軍教授),作者包括高軍教授(通訊作者)、陳河堆(中興通訊)、屠要峰(中興通訊,通訊作者)
7. MiCS: 面向公有雲超大模型訓練的近線形擴展通信系統

超大模型訓練具有很大的網絡開銷,而公有雲的網絡環境複雜,導緻使用現有框架訓練超大模型時難以高效擴展。文章 MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud提出了一個面向公有雲訓練超大模型的近線形擴展通信優化系統MiCS。通過減少通信集合中的參與者數量,MiCS可以利用異構網絡帶寬,減少慢速鍊路上的網絡流量,減少通信延遲以保持高網絡帶寬利用率,并攤銷昂貴的全局梯度同步代價。實驗結果表明,MiSC在公有雲上的系統吞吐超過現有方法,達到接近線形的擴展效率。
該論文第一作者為約翰霍普金斯大學博士張桢(導師金鑫副教授),通訊作者為金鑫副教授和AWS的Shuai Zheng,合作作者包括AWS的Yida Wang、Justin Chiu、George Karypis、Trishul Chilimbi、Mu Li。


