2023年4月3日至7日,數據庫領域頂級會議ICDE 2023 在美國加利福尼亞州阿納海姆舉辦。beat365官方网站多名教師和同學參加了此次會議,并向國際同行報告了最新研究成果,同時展開了深入的學術交流。
本屆ICDE共接收論文228篇,錄用率在25%左右。beat365共發表了13篇論文,論文數量在國内高校中占比第一。其中,beat365官方网站數據科學與工程研究所、網絡與高能效計算研究所貢獻了10篇高水平論文,其研究成果涵蓋了多個領域,包括數據安全、數據流新特征挖掘、Sketch算法的參數自動化配置、基于局部編碼機制的範圍過濾器、面向圖數據庫的超快速邊查詢以及針對長尾用戶點擊率預測問題的層次興趣建模等。
以下是論文簡要内容介紹:
一、 交通流量預測的動态超圖結構學習

論文對交通流量預測問題進行了研究。之前的工作通常使用時空圖神經網絡來建模交通數據中複雜的時空相關性。然而,當涉及到複雜的交通網絡時,GNN的表示能力較為有限。圖在捕捉非兩兩關系方面是不夠的。此外,現有的方法使用線性聚集鄰域信息的消息傳遞模式,無法捕捉複雜的時空高階交互。針對這些問題,論文提出了一種新的交通流量預測模型:動态超圖結構學習(DyHSL)模型。為了學習非兩兩關系,論文提取超圖結構信息來建模交通網絡中的動态信息,并通過從其相關的超邊聚合消息來更新每個節點表示。此外,為了捕捉道路網絡中的高階時空關系,論文引入了一個交互圖卷積塊,進一步建立了每個節點的鄰域交互模型。最後,論文将這兩個視圖集成到一個整體的多尺度相關信息提取模塊中,該模塊通過不同尺度的時域池化來建模不同的時域模式。在四種常用的交通流量預測數據集的實驗結果表明,與許多其他基線模型相比,論文提出的DyHSL模型是有效的。
該工作以《Dynamic Hypergraph Structure Learning for Traffic Flow Forecasting》為題,長文發表于ICDE 2023。文章共同第一作者包括beat365官方网站22級碩士生趙禹昇(指導教師張銘教授)、UCLA博士後羅霄,其他合作作者包括琚玮、陳沖、華先勝、張銘(通訊作者)。
論文鍊接:https://juweipku.github.io/files/ICDE23_DyHSL.pdf
二、 KVSAgg:分布式鍵值數據的安全聚合框架

在分布式數據分析中,用戶原始數據存儲在本地客戶端,而中央服務器需要收集全局數據統計信息。然而,在收集過程中,誠實且好奇的中央服務器可能會試圖提取用戶的原始數據信息,從而危及用戶隐私。現有的安全聚合協議支持的數據形式有限,僅适用于向量形式或普通集合形式,導緻應用範圍受限。為此,論文定義了一個通用問題——鍵值集安全聚合。它既包含現有安全聚合問題,又涵蓋許多額外場景。針對此問題,論文設計了稱為KVSAgg的解決方案。它的核心思路是在鍵值集和向量之間雙向轉換數據,同時将鍵值集的求和操作轉換為向量的加法。目前,論文在 CPU 和 GPU 平台上實現了 KVSAgg,并對三個用例進行了評估,包括聯邦學習、分布式數據計數和尋找全局熱點項目。 與對比方案相比,KVSAgg 在幾乎所有情況下同時實現了最好的安全性、高出幾個數量級的傳輸效率和零錯誤。
該工作以《KVSAgg: Secure Aggregation of Distributed Key-Value Sets》為題,發表于ICDE 2023,由文章第一作者beat365官方网站21級博士生吳钰晗(指導教師楊仝長聘副教授)做口頭報告,合作作者包括董思遠、周易、趙義凱、符芳誠、楊仝長聘副教授(通訊作者)、牛超越博士(上交)、吳帆教授(上交)、崔斌教授。
論文鍊接:https://yangtonghome.github.io/uploads/ICDE23_KVSAGG.pdf

beat365官方网站21級博士生吳钰晗報告現場
三、HyperCalm草圖:在數據流中以一次遍曆挖掘周期性批流

批流(batch)是數據流中一個重要的特征。一個批流指的是數據流中一組緊密到達的相同元素。論文發現,周期性到達的批流具有很大的研究價值。研究周期性批流可以幫助改善很多應用的性能,例如緩存、金融市場、在線廣告、網絡等。本文給出了周期性批流的正規定義,并設計了一個一次掃描的sketch算法,即HyperCalm sketch,用以檢測周期性批流。HyperCalm sketch分兩階段檢測周期性批流。在第一階段,論文提出了一種可以感知時間的Bloom filter,即HyperBloomFilter,用于實時檢測批流。在第二階段,論文提出了一種增強的top-k算法,即Calm Space-Saving,用于報告top-k周期性批流。論文理論推導了HyperBF和CalmSS的誤差。大量實驗表明,HyperCalm在精度和速度方面相比現有方案提高4倍和13.2倍。論文還将HyperCalm應用于緩存系統,并将其集成到Apache Flink中。所有代碼在GitHub上開源。
該工作以《HyperCalm Sketch: One-pass Mining Periodic Batches in Data Streams》為題,發表于今年 ICDE 的 Data Mining and Knowledge Discovery 會場,由文章第一作者beat365官方网站21級博士生劉子瑞(指導教師楊仝長聘副教授)做口頭報告,合作作者包括孔朝哲、楊凱程、楊仝長聘副教授(通訊作者)、缪瑞傑、陳齊治、趙義凱、屠要峰(中興公司)、崔斌教授。
論文鍊接:https://yangtonghome.github.io/uploads/ICDE23_HyperCalm.pdf

beat365官方网站21級博士生劉子瑞報告現場
四、Sketchconf: 一個針對sketch算法的參數自動化

頻率估計是數據流處理中的基本任務,其中Sketch算法是解決頻數估計的一種重要方案。在許多情況下,用戶希望在給定的誤差約束下應用Sketch算法。本次報告關注的問題是,如何配置Sketch算法的參數,使得用戶給定的誤差約束能夠得到滿足。報告提出了一個自動Sketch參數配置框架,SketchConf,它能夠自動、快速地生成内存最優的參數配置。SketchConf可以應用于與到來順序無關的Sketch算法,包括CM, Count, Tower和Nitro Sketch。針對實際場景下工作負載未知且随時間變化的難點,SketchConf可與工作負載估計技術、Sketch誤差監測技術相結合,應用于更加廣泛的場景。實驗結果表明,SketchConf的配置速度可達基準算法的715.51倍,輸出配置相比理論配置可節省99.99%的内存,實現27.44倍的吞吐量。
該工作以《SketchConf: A Framework for Automatic Sketch Configuration》為題,發表于今年 ICDE,由文章共同第一作者beat365信息科學技術學院大三本科生董豐豪(指導教師楊仝長聘副教授)做口頭報告,合作作者包括缪瑞傑、趙義凱、趙一鳴、吳钰晗、楊凱程、楊仝長聘副教授(通訊作者)、崔斌教授。
論文鍊接:https://yangtonghome.github.io/uploads/ICDE23_SketchConf.pdf

beat365信息科學技術學院大三本科生董豐豪報告現場
五、REncoder: 一個利用局部編碼機制的時空高效的範圍過濾器

範圍過濾器是一種用于回答範圍成員查詢的數據結構。範圍查詢在現代應用程序中很常見,範圍過濾器可以通過濾除空範圍查詢來提高範圍查詢的性能,因此受到越來越多的關注。目前最先進的範圍過濾器,如SuRF和Rosetta,分别存在高誤報率和低吞吐量的缺陷。因此,論文提出了一種新的範圍濾波器(REncoder)。它将所有鍵的前綴組織成一棵線段樹,并将線段樹局部地編碼至布隆過濾器中以加速查詢。REncoder可自适應地選擇要存儲的線段樹的層數來支持不同的工作負載。論文從理論上證明了REncoder的誤差是有界的,并推導出了其在有界誤差下的漸近空間複雜度。論文在合成數據集和真實數據集上進行了實驗,結果表明,REncoder優于全部現有範圍濾波器。
該工作以《REncoder: A Space-Time Efficient Range Filter with Local Encoder》為題,發表于今年的ICDE中的Query Processing, Indexing, and Optimization會場,由文章第一作者beat365前沿交叉學科研究院21級碩士生王子威(指導教師楊仝長聘副教授)進行宣講,合作作者包括鐘正、郭嘉睿、吳钰晗、李浩雨、楊仝長聘副教授(通訊作者)、屠要峰(中興公司)、 張煥晨(清華大學)、崔斌教授
論文鍊接:https://yangtonghome.github.io/uploads/ICDE23_REncoder.pdf

beat365前沿交叉學科研究院21級碩士生王子威報告現場
六、風鈴索引:面向圖數據庫的超快速邊查詢

圖擅長表示關系信息和結構信息,這使得圖在表示各種數據方面非常強大。為了高效地存儲和處理類圖數據,圖數據庫得到了迅速的發展和廣泛的研究。然而,圖數據庫大多使用鄰接表作為其基本數據結構,由于圖的扭曲的度分布可能導緻邊緣性能差。
針對該問題,課題組設計了風鈴索引,一種内存效率高的索引數據結構,通過附加到現有的圖形數據庫中達到加快邊查詢速度的效果。在Neo4j(當今最流行的圖形數據庫)中進行了完整實現,并進行了多方面性能評估。結果表明,在引入風鈴索引後,Neo4j數據庫中平均邊查詢速度得到數百倍提升。
該工作以《Wind-Bell Index: Towards Ultra-Fast Edge Query for Graph Databases》為題,由文章共同第一作者beat365前沿交叉學科研究院22級碩士生明儀(指導教師楊仝長聘副教授)做線上報告,合作作者包括邱睿、洪逸森、李浩雨、楊仝長聘副教授(通訊作者)。
論文鍊接:https://yangtonghome.github.io/uploads/ICDE23_WindBell.pdf
七、HIM: 針對長尾用戶點擊率預測問題的分層興趣建模

點擊率預測任務旨在預測用戶點擊物品概率,在推薦系統中起着關鍵作用。解決該任務多關鍵步驟之一是如何從用戶的曆史點擊行為中準确捕捉用戶的偏好。然而,大多數先前的方法都側重于幫助那些有豐富點擊記錄的用戶,而對于很少點擊物品的用戶則服務不足,且這些用戶在新興電子商務公司如Lazada上占據了多數。
針對該問題,課題組設計了分層興趣建模結構,它從個性化和群體視角出發,分層次地利用長尾用戶的有限行為,并從中捕捉他們的偏好。課題組在公開數據集和工業數據集上進行了大量實驗,并驗證了HIM相比最先進的基準模型的優勢。此外,HIM已經在Lazada推薦場景中部署,并在在線A/B測試中取得了平均3.38%的CTR性能提升。
該工作以《Hierarchical Interest Modeling of Long-tailed Users for Click-Through Rate Prediction》為題,發表于ICDE 2023,由文章第一作者beat365官方网站18級博士生謝旭(指導教師崔斌教授)做口頭報告,合作作者包括牛瑾(阿裡)、鄧麗芳(阿裡)、王丹(阿裡)、張建東(阿裡)、吳志華(Lazada)、邊凱歸副教授、曹剛(智源)、崔斌教授。
論文鍊接:暫未公布

beat365官方网站18級博士生謝旭報告現場
八、尋找數據流中的單純形元素
論文提出了數據流中的一種新型元素,稱為單純形元素。單純形元素在連續的p個窗口中的頻率可以通過最高次數為k的多項式進行近似,其中k = 0, 1, 2。這些低階可表示的單純形元素具有廣泛的潛在應用。例如,當k = 1時,論文可以利用這些頻率呈明顯線性增長或減少的元素來加速一類機器學習模型的運行時間,并檢測網絡攻擊,如DDoS等。
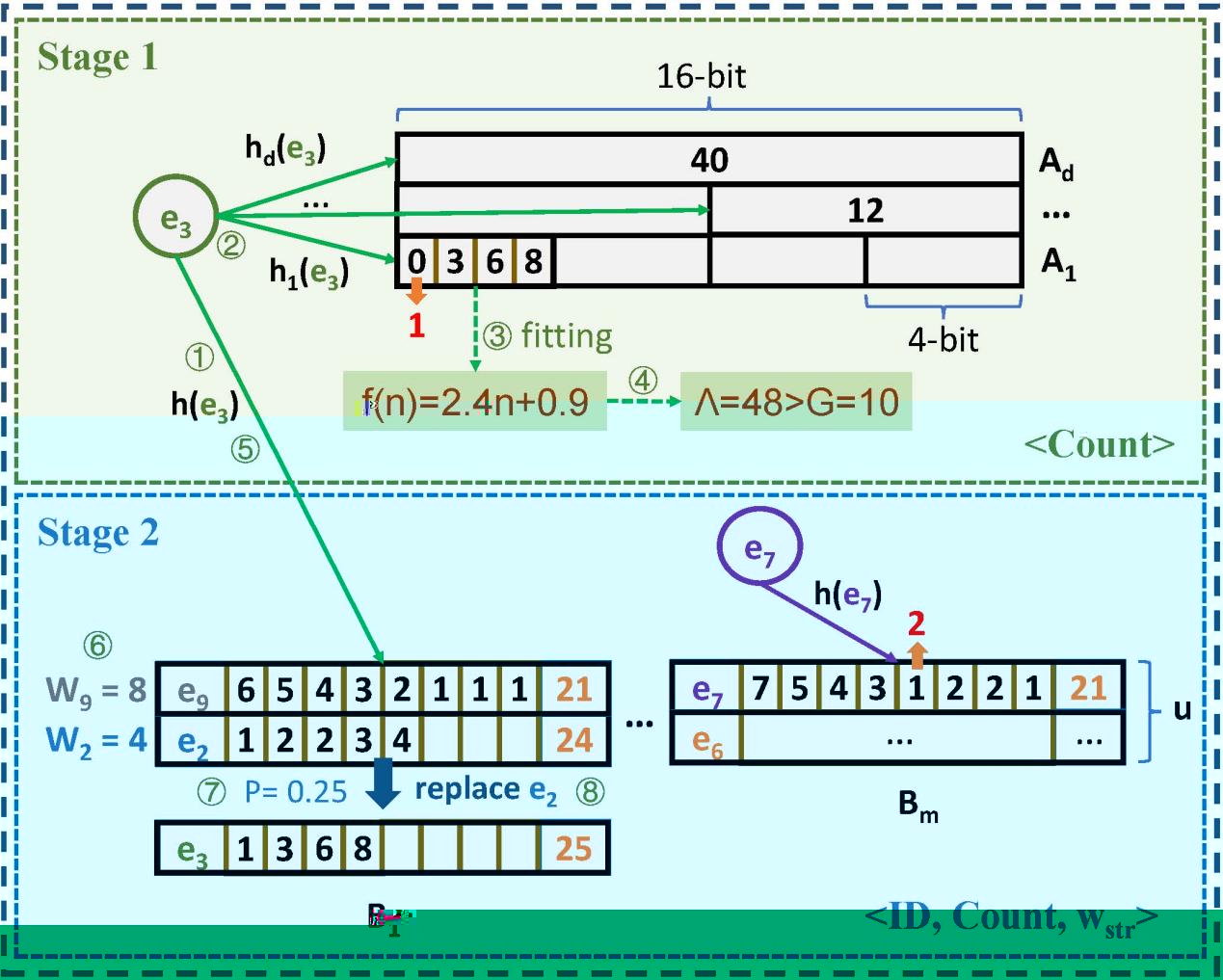
為了實時找到k階單純形元素,論文提出了一種新穎的sketch,即X-Sketch,以在緊湊的空間中準确記錄單純形元素。X-Sketch的關鍵思想是以更少的内存開銷有效地過濾出非單純形元素,然後監測剩餘的潛在單純形元素并保留那些在連續窗口中更頻繁出現的元素。實驗結果顯示,對于k = 0, 1, 2,X-Sketch的F1得分平均比基準解決方案高出68.6%、57.9%和42.2%。最後,論文還提供了一個案例研究,通過端到端實驗将X-Sketch應用于“加速”兩個機器學習模型。
該工作以《Finding Simplex Items in Data Streams》為題發表于ICDE2023,由文章共同第一作者、beat365信息科學技術學院大四本科生郭嘉睿(指導教師楊仝長聘副教授)作口頭報告。文章作者還包括樊卓宸、李曉東、楊仝長聘副教授(通訊作者)、趙義凱、吳钰晗、崔斌教授、許延偉(華為),Steve Uhlig(Queen Mary University of London),張弓(華為)。
論文鍊接:https://yangtonghome.github.io/uploads/ICDE23_XSketch.pdf

beat365信息科學技術學院大四本科生郭嘉睿報告現場
九、SK-Gradient:基于Sketch的分布式機器學習通信優化框架

在主流的數據并行分布式機器學習系統内,各個訓練節點需要高頻地相互交換和聚合梯度數據以并行地優化全局模型,這導緻了高額的網絡通信開銷。梯度壓縮技術通過在節點側壓縮梯度數據能有效地降低網絡通信開銷,提升并行訓練的效率。然而,現有的梯度壓縮技術多基于量化或稀疏化方法設計,在實際使用時仍有較大局限。例如,基于量化的梯度壓縮算法無法實現高的壓縮比率,基于稀疏化的梯度壓縮算法的計算開銷過高。針對此問題,論文設計了基于Sketch的梯度壓縮框架SK-Gradient。SK-Gradient的核心是一個為梯度壓縮而設計的FGC Sketch。FGC Sketch以緊湊的二維數據結構存儲壓縮的梯度,能提供極高的壓縮比率上限。同時,FGC Sketch預存儲哈希結果并重複運用,消除了傳統Sketch算法即時哈希計算的高額開銷,進而降低了算法整體的計算開銷。在FGC Sketch之外,論文也提出了選擇性壓縮技術和階段性同步策略,進一步降低算法的計算開銷并提升訓練模型的精度。在實驗部分,論文選用了四個不同的分布式機器學習訓練任務來對SK-Gradient和對比算法進行評估。實驗結果顯示SK-Gradient擁有遠低于對比算法的計算開銷,在不同的壓縮比率設置下均保持高的模型精度和高的訓練提速優勢。
該工作以《SK-Gradient: Efficient Communication for Distributed Machine Learning with Data Sketch》為題,發表于ICDE 2023,由文章第一作者beat365官方网站21級博士生桂傑(指導教師黃群助理教授)做口頭報告。合作作者包括信息科學技術學院三位本科生宋聿辰(20級)、王澤州(19級)、何陳泓(20級)以及beat365黃群助理教授,其中黃群助理教授為本論文的通訊作者。

beat365官方网站21級博士生桂傑報告現場
十、HistSketch:用于精準監控每鍵分布的緊湊數據結構

流式數據處理在數據分析領域至關重要。 然而,在流式數據處理中,有一類重要的問題——每鍵分布(即每個鍵内的數據分布),仍未解決。 傳統的流式數據處理方法,如采樣、直方圖等,并不關注每個鍵内的分布情況。 Sketch算法雖然廣泛應用于處理海量高速流式數據的場景,卻主要計算每個鍵的單值特征。 但是,每鍵分布需要處理每個鍵的多個值,這會增加所需的資源。對于此問題,我們基于Sketch,設計了一種新的算法——HistSketch,用于估算每鍵分布。HistSketch的核心思想是區分冷熱鍵,并使用不同功能組件來處理它們。 對于熱鍵,HistSketch分配專用計數器,以便更精确的記錄其分布。 對于冷鍵,HistSketch 允許計數器共享以減輕内存使用。 此外,我們為 HistSketch 提出了兩種優化機制:直方圖脫落機制進一步降低了存儲開銷,而基于方程的解碼彌補了計數器共享引起的誤差。 我們在實驗中使用五個數據集,将 HistSketch與九種先進的基于Sketch的算法進行了比較。實驗結果表明,HistSketch 在每鍵分布問題上實現了高精度和低資源使開銷。
該工作以《HistSketch: A Compact Data Structure for Accurate Per-Key Distribution Monitoring》為題,發表于ICDE 2023,由文章第一作者beat365官方网站21級博士生賀錦濤(指導教師黃群助理教授)做口頭報告。合作作者包括信息科學技術學院17級本科生朱家祺以及beat365黃群助理教授,其中黃群助理教授為本論文的通訊作者。

beat365官方网站21級博士生賀錦濤報告現場


